

XIV. Zippeurs▲
Alors que la pureté d'Haskell amène tout un tas de bienfaits, elle nous oblige à attaquer certains problèmes sous un autre angle que celui qu'on aurait pris dans des langages impurs. À cause de la transparence référentielle, une valeur est aussi bonne qu'une autre en Haskell si elles représentent toutes les deux la même chose.
Donc si on a un arbre plein de cinq (tapez-m'en cinq ?) et qu'on veut en changer un en un six, il nous faut un moyen de savoir exactement quel cinq dans notre arbre on veut changer. Il faut savoir où il est dans l'arbre. Dans les langages impurs, on aurait pu noter l'adresse mémoire où est situé le cinq, et changer la valeur à cette adresse. Mais en Haskell, un cinq est un cinq comme les autres, et on ne peut donc pas le discriminer en fonction de sa position en mémoire. On ne peut pas non plus vraiment changer quoi que ce soit, et quand on dit qu'on change un arbre, on veut en fait dire qu'on prend un arbre et qu'on en retourne un autre, similaire à l'original, mais un peu différent.
Une possibilité consiste à se rappeler du chemin de la racine de l'arbre à l'élément qu'on souhaite changer. On pourrait dire : prends cet arbre, va à gauche, va à droite, et encore à gauche, et change l'élément qui est à cet endroit. Bien que cela marche, ça peut être inefficace. Si l'on veut plus tard changer un élément qui est juste à côté de celui qu'on vient de changer, on doit traverser l'arbre à nouveau depuis la racine jusqu'à cet élément !
Dans ce chapitre, nous allons voir qu'on peut prendre une structure de données et se focaliser sur une partie de celle-ci de façon à ce que modifier ses éléments soit facile, et à ce que se balader autour soit efficace. Joli !
XIV-A. Une petite balade▲
Comme on l'a appris en cours de biologie, il y a beaucoup de sortes différentes d'arbres, alors choisissons une graine qu'on utilisera pour planter le nôtre. La voici :
data Tree a = Empty | Node a (Tree a) (Tree a) deriving (Show)Notre arbre est donc ou bien vide, ou bien un nœud qui a un élément et deux sous-arbres. Voici un bon exemple d'un tel arbre, que je donne, à vous lecteur, gratuitement !
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
freeTree :: Tree Char
freeTree =
Node 'P'
(Node 'O'
(Node 'L'
(Node 'N' Empty Empty)
(Node 'T' Empty Empty)
)
(Node 'Y'
(Node 'S' Empty Empty)
(Node 'A' Empty Empty)
)
)
(Node 'L'
(Node 'W'
(Node 'C' Empty Empty)
(Node 'R' Empty Empty)
)
(Node 'A'
(Node 'A' Empty Empty)
(Node 'C' Empty Empty)
)
)
Et voici ce même arbre représenté graphiquement :
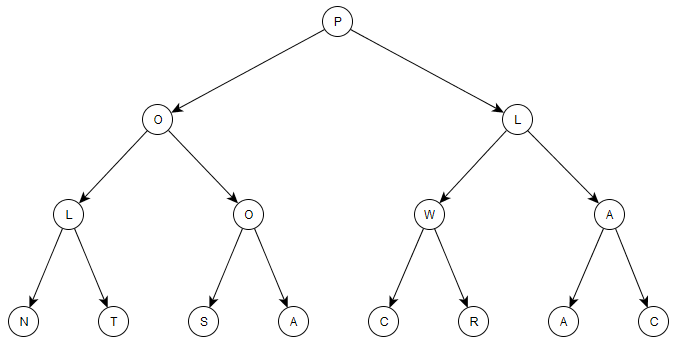
Remarquez-vous le W dans cet arbre ? Disons qu'on souhaite le changer en un P. Comment ferions-nous cela ? Eh bien, une façon de faire consisterait à filtrer par motif sur notre arbre jusqu'à ce qu'on trouve l'élément situé en allant d'abord à droite puis à gauche, et qu'on change cet élément. Voici le code faisant cela :
changeToP :: Tree Char -> Tree Char
changeToP (Node x l (Node y (Node _ m n) r)) = Node x l (Node y (Node 'P' m n) r)Beurk ! Non seulement c'est plutôt laid, mais c'est aussi un peu déroutant. Qu'est-ce qu'il se passe ici ? Eh bien, on filtre par motif sur notre arbre et on appelle sa racine x (il devient le 'P' de la racine) et son sous-arbre gauche l. Plutôt que de donner un nom au sous-arbre droit, on le filtre à nouveau par motif. On continue ce filtrage jusqu'à atteindre le sous-arbre dont notre 'W' est la racine. Une fois ceci fait, on recrée l'arbre, seulement le sous-arbre qui contenait le 'W' a maintenant pour racine 'P'.
Y a-t-il un meilleur moyen de faire ceci ? Pourquoi ne pas créer une fonction qui prenne un arbre ainsi qu'une liste de directions ? Les directions seront soit L soit R, représentant respectivement la gauche et la droite, et on changera l'élément sur lequel on tombe en suivant ces directions. Voici :
2.
3.
4.
5.
6.
7.
data Direction = L | R deriving (Show)
type Directions = [Direction]
changeToP :: Directions -> Tree Char -> Tree Char
changeToP (L:ds) (Node x l r) = Node x (changeToP ds l) r
changeToP (R:ds) (Node x l r) = Node x l (changeToP ds r)
changeToP [] (Node _ l r) = Node 'P' l r
Si le premier élément de notre liste de directions est un L, on construit un nouvel arbre comme l'original, mais son sous-arbre gauche a un élément modifié en 'P'. Quand on appelle récursivement changeToP, on ne donne que la queue de la liste des directions, puisqu'on est déjà allé une fois à gauche. On fait la même chose dans le cas de R. Si la liste des directions est vide, cela signifie qu'on est arrivé à destination, on retourne donc un arbre qui est comme celui en entrée, mais avec 'P' à sa racine.
Pour éviter d'afficher l'arbre entier, créons une fonction qui prend une liste de directions et nous dit quel est l'élément à la destination :
2.
3.
4.
elemAt :: Directions -> Tree a -> a
elemAt (L:ds) (Node _ l _) = elemAt ds l
elemAt (R:ds) (Node _ _ r) = elemAt ds r
elemAt [] (Node x _ _) = x
La fonction est en fait assez similaire à changeToP, seulement au lieu de se souvenir des choses en chemin et de reconstruire l'arbre, elle ignore simplement tout sauf sa destination. Ici on change le 'W' en 'P' et on vérifie si le changement a bien eu lieu dans le nouvel arbre :
2.
3.
ghci> let newTree = changeToP [R,L] freeTree
ghci> elemAt [R,L] newTree
'P'
Bien, ça a l'air de marcher. Dans ces fonctions, la liste des directions agit comme une sorte de point focal, parce qu'il désigne exactement un sous-arbre de notre arbre. Une liste de directions comme [R] se focalise sur le sous-arbre droit de la racine, par exemple. Une liste de directions vide se focalise sur l'arbre entier.
Bien que cette technique ait l'air cool, elle peut être assez inefficace, notamment si l'on veut changer des éléments à répétition. Disons qu'on ait un arbre énorme et une très longue liste de directions qui pointe vers un élément tout en bas de cet arbre. On utilise la liste de directions pour se balader dans l'arbre et changer l'élément en bas. Si l'on souhaite changer un autre élément proche de cet élément, on doit repartir de la racine et retraverser tout l'arbre depuis le début à nouveau ! La barbe !
XIV-B. Une traînée de miettes▲
OK, donc pour se concentrer sur un sous-arbre, on veut quelque chose de mieux qu'une liste de directions qu'on suit toujours depuis la racine de notre arbre. Est-ce que cela aiderait si l'on commençait à la racine de l'arbre, et qu'on se déplaçait vers la gauche ou la droite, une étape à la fois, en laissant d'une certaine façon des miettes de pain sur notre passage ? C'est-à-dire, quand on va à gauche, on se souvient qu'on est allé à gauche, et quand on va à droite, on se souvient qu'on est allé à droite. Bien, on peut essayer.
Pour représenter nos miettes de pain, on va aussi utiliser une liste de Direction (soit L, soit R), seulement au lieu de l'appeler Directions, on l'appellera Breadcrumbs, puisque nos directions seront à présent renversées puisqu'on jette les miettes au fur et à mesure qu'on avance dans l'arbre :
type Breadcrumbs = [Direction]Voici une fonction qui prend un arbre et des miettes et se déplace dans le sous-arbre gauche tout en ajoutant L dans la liste qui représente nos miettes de pain :
goLeft :: (Tree a, Breadcrumbs) -> (Tree a, Breadcrumbs)
goLeft (Node _ l _, bs) = (l, L:bs)On ignore l'élément à la racine ainsi que le sous-arbre droit, et on retourne juste le sous-arbre gauche ainsi que l'ancienne traînée de miettes, avec L placé à sa tête. Voici une fonction pour aller à droite :
goRight :: (Tree a, Breadcrumbs) -> (Tree a, Breadcrumbs)
goRight (Node _ _ r, bs) = (r, R:bs)Elle fonctionne de façon similaire. Utilisons ces fonctions pour prendre notre freeTree et aller à droite puis à gauche :
ghci> goLeft (goRight (freeTree, []))
(Node 'W' (Node 'C' Empty Empty) (Node 'R' Empty Empty),[L,R])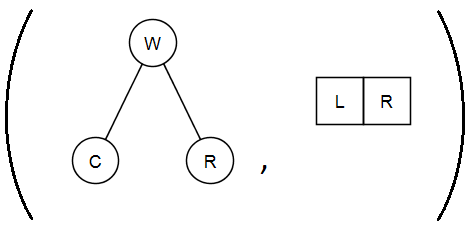
OK, donc maintenant on a un arbre qui a 'W' à sa racine, 'C' à la racine de son sous-arbre gauche, et 'R' à la racine de son sous-arbre droit. Les miettes de pain sont [L, R] parce qu'on est d'abord allé à droite, puis à gauche.
Pour rendre plus clair le déplacement dans notre arbre, on peut réutiliser la fonction -: qu'on avait définie ainsi :
x -: f = f xCe qui nous permet d'appliquer des fonctions à des valeurs en écrivant d'abord la valeur, puis -: et enfin la fonction. Ainsi, au lieu d'écrire goRight (freeTree, []), on peut écrire (freeTree, []) -: goRight. En utilisant ceci, on peut réécrire le code ci-dessus de façon à faire mieux apparaître qu'on va en premier à droite, et ensuite à gauche :
ghci> (freeTree, []) -: goRight -: goLeft
(Node 'W' (Node 'C' Empty Empty) (Node 'R' Empty Empty),[L,R])XIV-B-1. Retourner en haut▲
Et si l'on veut remonter dans l'arbre à présent ? Grâce à notre traînée de miettes, on sait que notre arbre actuel est le sous-arbre gauche de son parent, et que celui-ci est le sous-arbre droit de son parent, mais c'est tout. Elles ne nous en disent pas assez sur le parent du sous-arbre pour qu'on puisse remonter dans l'arbre. Il semblerait qu'en plus de la direction prise, notre miette de pain devrait aussi contenir toutes les données nécessaires pour remonter dans l'arbre. Dans ce cas, il nous faudrait l'élément de l'arbre parent ainsi que le sous-arbre droit.
En général, une miette de pain doit contenir toutes les données nécessaires pour reconstruire son nœud parent. Elle doit donc contenir toute l'information sur les chemins que l'on n'a pas suivis, ainsi que la direction que l'on a prise, mais elle n'a pas besoin de contenir le sous-arbre sur lequel on se focalise, puisqu'on a déjà ce sous-arbre dans la première composante de notre tuple, donc s'il était aussi dans la miette, il y aurait une duplication de l'information.
Modifions notre miette de pain afin qu'elle contienne aussi l'information sur tout ce qu'on a ignoré précédemment quand on a choisi d'aller à gauche ou à droite. Au lieu de Direction, définissons un nouveau type de données :
data Crumb a = LeftCrumb a (Tree a) | RightCrumb a (Tree a) deriving (Show)Maintenant, au lieu d'avoir juste un L, on a un LeftCrumb qui contient également l'élément dans le nœud parent, ainsi que son sous-arbre droit qu'on a choisi de ne pas visiter. Au lieu de R, on a un RightCrumb, qui contient aussi l'élément du nœud parent et son sous-arbre gauche qu'on n'a pas visité.
Ces miettes de pain contiennent à présent toutes les données nécessaires pour recréer l'arbre qu'on a parcouru. Ainsi, au lieu d'être juste des miettes de pain normales, ce sont plutôt des petits disques durs qu'on parsème en chemin, parce qu'ils contiennent beaucoup plus d'informations que seulement la direction prise.
En gros, chaque miette de pain est maintenant comme un nœud d'arbre, mais avec un trou d'un côté. Lorsqu'on se déplace en profondeur dans l'arbre, la miette transporte toute l'information du nœud duquel on est parti, sauf le sous-arbre sur lequel on se focalise. Elle doit aussi savoir de quel côté se trouve le trou. Dans le cas d'un LeftCrumb, on sait qu'on est allé à gauche, donc le sous-arbre manquant est le sous-arbre gauche.
Changeons également notre synonyme de type Breadcrumbs pour refléter le changement :
type Breadcrumbs a = [Crumb a]À présent, on doit modifier les fonctions goLeft et goRight afin qu'elles stockent l'information sur les chemins que l'on n'a pas pris dans nos miettes, au lieu de tout ignorer comme elles le faisaient auparavant. Voici goLeft :
goLeft :: (Tree a, Breadcrumbs a) -> (Tree a, Breadcrumbs a)
goLeft (Node x l r, bs) = (l, LeftCrumb x r:bs)Vous pouvez voir que ça ressemble beaucoup à notre ancienne goLeft, seulement au lieu d'ajouter seulement un L en tête de notre liste de miettes, on ajoute un LeftCrumb qui indique qu'on est allé à gauche, et on munit ce LeftCrumb de l'élément du nœud qu'on quitte (le x) et de son sous-arbre droit qu'on a choisi de ne pas visiter.
Remarquez que cette fonction suppose que l'arbre sur lequel on se focalise actuellement n'est pas Empty. Un arbre vide n'a pas de sous-arbres, donc si l'on essaie d'aller à gauche dans un arbre vide, une erreur aura lieu parce que le filtrage par motif sur Node échouera, et parce qu'on n'a pas mis de motif pour Empty.
goRight est similaire :
goRight :: (Tree a, Breadcrumbs a) -> (Tree a, Breadcrumbs a)
goRight (Node x l r, bs) = (r, RightCrumb x l:bs)Précédemment, nous étions capable d'aller à gauche ou à droite. Ce qu'on a gagné, c'est la possibilité de rebrousser chemin, en se souvenant de ce à quoi ressemblaient les nœuds parents et les chemins qu'on n'a pas visités. Voici la fonction goUp :
2.
3.
goUp :: (Tree a, Breadcrumbs a) -> (Tree a, Breadcrumbs a)
goUp (t, LeftCrumb x r:bs) = (Node x t r, bs)
goUp (t, RightCrumb x l:bs) = (Node x l t, bs)
On se focalise sur l'arbre t, et on vérifie ce qu'était le dernier Crumb. Si c'était un LeftCrumb, alors on construit un nouvel arbre où notre arbre t est le sous-arbre gauche, et on utilise l'information à propos du sous-arbre droit qu'on n'a pas visité et de l'élément pour reconstruire le reste du Node. Puisqu'on a en quelque sorte rebroussé chemin et ramassé la dernière miette pour récréer le nœud parent, la nouvelle liste de miettes ne contient pas cette miette.
Remarquez que cette fonction cause une erreur si l'on est déjà à la racine d'un arbre et qu'on essaie de remonter. Plus tard, on utilisera la monade Maybe pour représenter un échec possible lorsqu'on change de point focal.
Avec une paire de Tree a et de Breadcrumbs a, on a toute l'information nécessaire pour reconstruire un arbre entier, tout en étant focalisé sur un de ses sous-arbres. Ce mécanisme nous permet de facilement nous déplacer à gauche, à droite, et vers le haut. Une telle paire contenant une partie focalisée d'une structure de données, et ses alentours est appelée un zippeur, parce que changer de point focal vers le haut et vers le bas fait penser à une braguette qui monte et descend. Il est donc pratique de créer un synonyme de types :
type Zipper a = (Tree a, Breadcrumbs a)Je préférerais appeler le synonyme de types Focus pour indiquer clairement qu'on se focalise sur une partie de la structure de données, mais le terme zippeur est globalement accepté pour décrire un tel mécanisme, on s'en tiendra donc à Zipper.
XIV-B-2. Manipuler des arbres sous focalisation▲
À présent qu'on sait se déplacer de haut en bas, créons une fonction qui modifie l'élément à la racine de l'arbre sur lequel on est actuellement focalisé :
2.
3.
modify :: (a -> a) -> Zipper a -> Zipper a
modify f (Node x l r, bs) = (Node (f x) l r, bs)
modify f (Empty, bs) = (Empty, bs)
Si l'on se focalise sur un nœud, on modifie son élément racine avec la fonction f. Si on se focalise sur un arbre vide, on ne fait rien. Désormais, on peut démarrer avec un arbre, se déplacer où l'on veut, et modifier l'élément à cet endroit, tout en restant focalisé sur cet élément de façon à pouvoir facilement se déplacer de haut en bas par la suite. Un exemple :
ghci> let newFocus = modify (\_ -> 'P') (goRight (goLeft (freeTree,[])))On va à gauche, puis à droite, et on modifie l'élément racine en le remplaçant par un 'P'. C'est encore plus lisible avec -: :
ghci> let newFocus = (freeTree,[]) -: goLeft -: goRight -: modify (\_ -> 'P')On peut ensuite remonter si l'on veut, et remplacer un élément par un mystérieux 'X' :
ghci> let newFocus2 = modify (\_ -> 'X') (goUp newFocus)Ou avec -: :
ghci> let newFocus2 = newFocus -: goUp -: modify (\_ -> 'X')Remonter est facile puisque les miettes qu'on a laissées forment la structure de données que l'on n'a pas visitée, seulement tout est renversé, un peu comme une chaussette à l'envers. C'est pourquoi, lorsqu'on veut remonter d'un cran, on n'a pas besoin de repartir de la racine et de redescendre presque tout en bas, il nous suffit de prendre le sommet de notre arbre inversé, en le remettant dans le bon sens et sous notre focalisation.
Chaque nœud a deux sous-arbres, même si ces sous-arbres sont vides. Ainsi, si l'on se focalise sur un arbre vide, on peut le remplacer par un sous-arbre non vide, en lui attachant un arbre comme feuille. Le code pour faire cela est simple :
attach :: Tree a -> Zipper a -> Zipper a
attach t (_, bs) = (t, bs)On prend un arbre et un zippeur, et on retourne un nouveau zippeur, dont le point focal est remplacé par l'arbre en question. Non seulement peut-on étendre des arbres ainsi, en remplaçant des sous-arbres vides par d'autres arbres, mais on peut aussi complètement remplacer des sous-arbres existants. Attachons un arbre tout à gauche de notre freeTree :
ghci> let farLeft = (freeTree,[]) -: goLeft -: goLeft -: goLeft -: goLeft
ghci> let newFocus = farLeft -: attach (Node 'Z' Empty Empty)newFocus est à présent focalisé sur l'arbre qu'on vient juste d'attacher, et le reste de l'arbre est stocké renversé dans les miettes de pain. Si l'on utilisait goUp pour remonter jusqu'à la racine de l'arbre, il serait exactement comme freeTree, mais avec un 'Z' en plus tout à gauche.
XIV-B-3. I'm going straight to the top, oh yeah, up where the air is fresh and clean!▲
Créer une fonction qui remonte tout en haut de notre arbre, peu importe l'endroit sur lequel on s'est focalisé, est assez facile. La voilà :
2.
3.
topMost :: Zipper a -> Zipper a
topMost (t,[]) = (t,[])
topMost z = topMost (goUp z)
Si notre traînée de miettes est vide, cela signifie qu'on est arrivé à la racine de l'arbre, on retourne donc le point focal actuel. Sinon, on remonte d'un cran pour obtenir le point focal du nœud parent, et on appelle récursivement topMost sur ce point focal. À présent, on peut se balader dans notre arbre, aller à gauche, à droite, en haut, appliquer modify et attach tout en se déplaçant, et quand on a fini de faire nos modifications, on peut utiliser topMost pour nous focaliser à nouveau sur la racine de l'arbre, et voir tous les changements effectués depuis cette meilleure perspective.
XIV-C. Se focaliser sur des listes▲
Les zippeurs peuvent être utilisés avec quasiment toutes les structures de données, il n'est donc pas surprenant qu'on puisse les utiliser pour se focaliser sur les sous-listes d'une liste. Après tout, les listes sont un peu comme des arbres, seulement là où le nœud d'un arbre a un élément (ou pas) et plusieurs sous-arbres, un nœud d'une liste n'a qu'un élément et qu'une sous-liste. Quand on avait implémenté nos propres listesStructures de données récursives, on avait défini le type de données ainsi :
data List a = Empty | Cons a (List a) deriving (Show, Read, Eq, Ord)Contrastez ceci avec la définition de notre arbre binaire, et vous verrez facilement que les listes peuvent être considérées comme des arbres pour lesquels chaque nœud n'a qu'un sous-arbre.
Une liste comme [1, 2, 3] peut être écrite 1:2:3:[]. Elle consiste en une tête de liste, qui est 1, et une queue, qui est 2:3:[]. À son tour, 2:3:[] a aussi une tête, qui est 2, et une queue, qui est 3:[]. Avec 3:[], la tête est 3 et la queue est la liste vide [].
Créons un zippeur de listes. Pour changer le point focal d'une sous-liste d'une liste, on peut aller soit en avant, soit en arrière (alors que pour les arbres, on pouvait aller en haut, à gauche ou à droite). La partie focalisée sera une sous-liste, avec une traînée de miettes qu'on aura laissée en avançant. En quoi consisterait donc une miette de liste ? Quand on travaillait avec des arbres binaires, on disait qu'une miette devait contenir l'élément racine du nœud parent, ainsi que tous les sous-arbres qu'on n'avait pas visités. Elle devait aussi se souvenir si l'on était allé à gauche ou à droite. Ainsi, elle doit contenir toute l'information du nœud parent, à l'exception du sous-arbre qu'on choisit de visiter.
Les listes sont plus simples que des arbres, donc on n'a pas besoin de se souvenir si l'on est allé à gauche ou à droite, parce qu'il n'y a qu'un chemin pour aller plus profondément dans la liste. Et puisqu'il n'y a qu'un sous-arbre par nœud, on n'a pas besoin de se souvenir de chemins qu'on n'aurait pas pris. Il semblerait que tout ce dont on a besoin de se souvenir est l'élément précédent. Si l'on a une liste comme [3, 4, 5], et qu'on sait que l'élément précédent était 2, on peut rebrousser chemin en plaçant simplement cet élément en tête de liste, obtenant [2, 3, 4, 5].
Puisqu'une miette de pain est juste un élément dans ce cas, on n'a pas vraiment besoin de la placer dans un type de données, comme on l'avait fait avec Crumb pour notre zippeur d'arbres :
type ListZipper a = ([a],[a])La première liste représente la liste sur laquelle on se focalise, et la seconde est la liste des miettes. Créons des fonctions pour avancer et reculer dans des listes :
2.
3.
4.
5.
goForward :: ListZipper a -> ListZipper a
goForward (x:xs, bs) = (xs, x:bs)
goBack :: ListZipper a -> ListZipper a
goBack (xs, b:bs) = (b:xs, bs)
Quand on avance, on se focalise sur la queue de la liste actuelle et on laisse la tête comme miette. Quand on rebrousse chemin, on prend la dernière miette, et on la replace en tête de liste.
Voici les deux fonctions en action :
2.
3.
4.
5.
6.
7.
8.
9.
ghci> let xs = [1,2,3,4]
ghci> goForward (xs,[])
([2,3,4],[1])
ghci> goForward ([2,3,4],[1])
([3,4],[2,1])
ghci> goForward ([3,4],[2,1])
([4],[3,2,1])
ghci> goBack ([4],[3,2,1])
([3,4],[2,1])
On voit que les miettes de pain dans le cas des listes ne sont rien de plus qu'une partie de la liste renversée. L'élément dont on part devient la tête des miettes, il est donc facile de revenir en arrière en reprenant la tête des miettes et en en faisant la tête de notre point focal.
On voit également mieux pourquoi on appelle ça un zippeur, parce que cela ressemble vraiment à une braguette montant et descendant.
Si vous étiez en train de créer un éditeur de texte, vous pourriez utiliser une liste de chaînes de caractères pour représenter les lignes du fichier de texte ouvert, et utiliser un zippeur pour savoir à quelle ligne le curseur se trouve actuellement. En utilisant un zippeur, il serait également facile d'insérer de nouvelles lignes n'importe où dans le texte ou d'effacer des lignes existantes.
XIV-D. Un système de fichiers élémentaire▲
Maintenant qu'on sait comment les zippeurs fonctionnent, utilisons des arbres pour représenter un système de fichiers très simple, et créons un zippeur pour ce système de fichiers, qui nous permettra de nous déplacer à travers les dossiers, comme on le fait généralement quand on parcourt un système de fichiers.
Une vue simpliste du système de fichiers usuel consiste à le voir comme composé principalement de fichiers et de dossiers. Les fichiers sont des unités de données qui ont un nom, alors que les dossiers sont utilisés pour organiser ces fichiers et peuvent contenir d'autres dossiers. Disons donc qu'un élément d'un système de fichiers est soit un fichier, avec son nom et ses données, soit un dossier, qui a un nom et tout un tas d'autres éléments pouvant être eux-mêmes des fichiers ou des dossiers. Voici le type de données qu'on utilisera et quelques synonymes de types pour savoir qui est quoi :
2.
3.
type Name = String
type Data = String
data FSItem = File Name Data | Folder Name [FSItem] deriving (Show)
Un fichier vient avec deux chaînes de caractères, qui représentent son nom et les données qu'il contient. Un dossier vient avec une chaîne de caractères, qui est son nom, et une liste d'éléments. Si cette liste est vide, on a un dossier vide.
Voici un dossier avec des fichiers et des sous-dossiers :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
myDisk :: FSItem
myDisk =
Folder "root"
[ File "goat_yelling_like_man.wmv" "baaaaaa"
, File "pope_time.avi" "god bless"
, Folder "pics"
[ File "ape_throwing_up.jpg" "bleargh"
, File "watermelon_smash.gif" "smash!!"
, File "skull_man(scary).bmp" "Yikes!"
]
, File "dijon_poupon.doc" "best mustard"
, Folder "programs"
[ File "fartwizard.exe" "10gotofart"
, File "owl_bandit.dmg" "mov eax, h00t"
, File "not_a_virus.exe" "really not a virus"
, Folder "source code"
[ File "best_hs_prog.hs" "main = print (fix error)"
, File "random.hs" "main = print 4"
]
]
]
C'est exactement ce que contient mon disque dur à l'instant.
XIV-D-1. Un zippeur pour notre système de fichiers▲
Maintenant qu'on a un système de fichiers, tout ce dont on a besoin est d'un zippeur afin de zipper et zoomer dans celui-ci, et d'ajouter, modifier ou supprimer des fichiers ou des dossiers. Tout comme avec les arbres binaires et les listes, on va semer des miettes qui contiennent l'information nécessaire concernant les choses qu'on n'a pas choisi de visiter. Comme on l'a dit, une miette doit contenir tout, à l'exception du sous-arbre sur lequel on se focalise. Elle doit aussi savoir où se situe le trou, afin de pouvoir replacer notre point focal au bon endroit quand on décidera de rebrousser chemin.
Dans ce cas, une miette de pain doit être un dossier dans lequel il manque le dossier qu'on a choisi d'explorer. Et pourquoi pas un fichier plutôt ? Eh bien, parce qu'une fois qu'on se focalise sur un fichier, on ne peut pas descendre plus profond dans le système de fichiers, donc une miette qui dirait qu'on vient d'un fichier ne serait pas logique. Un fichier est en quelque sorte un arbre vide.
Si l'on se focalise sur le dossier "root", puis qu'on choisit de se focaliser sur le fichier "dijon_poupon.doc", à quoi devrait ressembler la miette qu'on laissera ? Eh bien, elle devrait contenir le nom du dossier parent ainsi que les éléments qui venaient avant le fichier sur lequel on se focalise et les éléments qui viennent après. Tout ce dont on a besoin est donc d'un Name et de deux listes d'éléments. En gardant séparée la liste des éléments venant avant et celle des éléments venant après, on sait exactement où placer l'élément sur lequel on était focalisé quand on retourne en arrière. Ainsi, on sait où se trouve le trou.
Voici notre type miette pour le système de fichiers :
data FSCrumb = FSCrumb Name [FSItem] [FSItem] deriving (Show)Et voici un synonyme de type pour notre zippeur :
type FSZipper = (FSItem, [FSCrumb])Remonter d'un cran dans la hiérarchie est très simple. On prend simplement la dernière miette et on assemble le nouveau point focal à partir du précédent et de la miette. Ainsi :
fsUp :: FSZipper -> FSZipper
fsUp (item, FSCrumb name ls rs:bs) = (Folder name (ls ++ [item] ++ rs), bs)Puisque notre miette savait le nom du dossier parent, ainsi que les éléments qui venaient avant l'élément sur lequel on s'était focalisé (c'est le ls) ainsi que ceux venant après (c'est le rs), remonter d'un cran était simple.
Qu'en est-il d'avancer plus profondément dans le système de fichiers ? Si nous sommes dans "root" et qu'on veut se focaliser sur "dijon_poupon.doc", la miette qu'on laissera devra inclure le nom "root" ainsi que les éléments précédant "dijon_poupon.doc" et ceux qui viennent après.
Voici une fonction qui, étant donné un nom, se focalise sur un fichier ou un dossier situé dans le dossier courant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
import Data.List (break)
fsTo :: Name -> FSZipper -> FSZipper
fsTo name (Folder folderName items, bs) =
let (ls, item:rs) = break (nameIs name) items
in (item, FSCrumb folderName ls rs:bs)
nameIs :: Name -> FSItem -> Bool
nameIs name (Folder folderName _) = name == folderName
nameIs name (File fileName _) = name == fileName
fsTo prend un Name et un FSZipper et retourne un nouveau FSZipper qui se focalise sur le fichier ou dossier portant ce nom. Ce fichier doit être dans le dossier courant. Cette fonction ne va pas le chercher dans tous les endroits possibles, elle regarde seulement dans le dossier courant.
Tout d'abord, on utilise break pour détruire la liste des éléments d'un dossier en ceux qui précèdent le fichier qu'on cherche et ceux qui le suivent. Si vous vous en souvenez, break prend un prédicat et une liste et retourne une paire de listes. La première liste de la paire contient les premiers éléments pour lesquels le prédicat a retourné False. Puis, dès que le prédicat retourne True pour un élément, elle place cet élément et tout le reste de la liste dans la deuxième composante de la paire. On a créé une fonction auxiliaire nommée nameIs qui prend un nom et un élément d'un système de fichiers et retourne True si le nom correspond.
À présent, ls est une liste contenant les éléments qui précèdent l'élément qu'on cherchait, item est l'élément en question, et rs est la liste des éléments venant après lui dans ce dossier. Muni de ceci, il ne nous reste plus qu'à présenter l'élément trouvé par break comme le point focal et à construire la miette appropriée.
Remarquez que si le nom qu'on cherche ne se trouve pas dans le dossier, le motif item:rs essaiera de filtrer une liste vide, et on aura une erreur. Si notre point focal n'est pas un dossier, mais un fichier, on aura une erreur et le programme plantera également.
On peut maintenant se déplacer de haut en bas dans notre système de fichiers. Partons de la racine et dirigeons-nous vers le fichier "skull_man(scary).bmp" :
ghci> let newFocus = (myDisk,[]) -: fsTo "pics" -: fsTo "skull_man(scary).bmp"newFocus est à présent un zippeur qui est focalisé sur le fichier "skull_man(scary).bmp". Récupérons le premier élément du zippeur (le point focal lui-même) et vérifions si c'est bien vrai :
ghci> fst newFocus
File "skull_man(scary).bmp" "Yikes!"Remontons d'un cran pour nous focaliser sur son voisin "watermelon_smash.gif" :
2.
3.
ghci> let newFocus2 = newFocus -: fsUp -: fsTo "watermelon_smash.gif"
ghci> fst newFocus2
File "watermelon_smash.gif" "smash!!"
XIV-D-2. Manipuler notre système de fichiers▲
À présent qu'on sait naviguer dans notre système de fichiers, le manipuler est très simple. Voici une fonction qui renomme le fichier ou dossier courant :
2.
3.
fsRename :: Name -> FSZipper -> FSZipper
fsRename newName (Folder name items, bs) = (Folder newName items, bs)
fsRename newName (File name dat, bs) = (File newName dat, bs)
On peut maintenant renommer "pics" en "cspi" :
ghci> let newFocus = (myDisk,[]) -: fsTo "pics" -: fsRename "cspi" -: fsUpOn est descendu jusqu'au dossier "pics", on l'a renommé, et on est remonté.
Pourquoi pas une fonction qui prend un nouvel élément, et l'ajoute au dossier courant ? Admirez :
2.
3.
fsNewFile :: FSItem -> FSZipper -> FSZipper
fsNewFile item (Folder folderName items, bs) =
(Folder folderName (item:items), bs)
C'était du gâteau. Remarquez que ceci planterait si l'on essayait d'ajouter un élément alors que notre point focal était un fichier plutôt qu'un dossier.
Ajoutons un fichier au dossier "pics" et retournons ensuite à la racine :
ghci> let newFocus = (myDisk,[]) -: fsTo "pics" -: fsNewFile (File "heh.jpg" "lol") -: fsUpCe qui est vraiment cool, c'est que lorsqu'on modifie notre système de fichiers, on ne le modifie pas vraiment en lieu et place, mais on retourne plutôt un nouveau système de fichiers. Ainsi, on a à la fois accès à l'ancien système de fichiers (ici, myDisk) et au nouveau (la première composante de newFocus). Ainsi, en utilisant des zippeurs, on obtient du versionnage sans effort, ce qui signifie qu'on peut toujours se référer aux anciennes versions de nos structures de données même après les avoir modifiées, pour ainsi dire. Ce n'est pas unique aux zippeurs, c'est simplement une propriété d'Haskell due au fait que ses structures de données sont immuables. Cependant, avec les zippeurs, on a la capacité de se déplacer efficacement dans des structures de données, et c'est là que la persistance des structures de données d'Haskell commence à dévoiler son potentiel.
XIV-E. Attention à la marche▲
Jusqu'ici, lorsqu'on traversait nos structures de données, qu'elles soient des arbres binaires, des listes ou des systèmes de fichiers, on ne se préoccupait pas trop d'avancer un pas trop loin et de tomber dans le vide. Par exemple, notre fonction goLeft prend un zippeur et un arbre binaire et déplace le point focal vers son sous-arbre gauche :
goLeft :: Zipper a -> Zipper a
goLeft (Node x l r, bs) = (l, LeftCrumb x r:bs)Et si l'arbre duquel on avançait était vide ? C'est-à-dire, et si ce n'était pas un Node, mais un Empty ? Dans ce cas, on obtiendrait une erreur à l'exécution parce que le filtrage par motif échouerait et parce qu'on n'avait pas mis de motif gérant le cas d'un arbre vide, qui ne contient pas de sous-arbres. Jusqu'ici, on a seulement supposé que l'on n'essaierait jamais de nous focaliser sur le sous-arbre gauche d'un arbre vide, puisque celui-ci n'existe pas. Mais, aller dans le sous-arbre gauche d'un arbre vide est illogique, et jusqu'alors, on a ignoré ce fait paresseusement.
Et si l'on était à la racine d'un arbre, sans miettes, et qu'on essayait de rebrousser chemin ? La même chose aurait lieu. Il semblerait que quand on utilise les zippeurs, chaque pas pourrait être notre dernier pas (une musique menaçante se fait entendre). En d'autres termes, tout mouvement peut réussir, mais peut aussi échouer. Cela ne vous rappelle rien ? Bien sûr, les monades ! Plus spécifiquement, la monade Maybe qui ajoute un contexte d'échec potentiel à nos valeurs.
Utilisons donc la monade Maybe pour ajouter un contexte possible d'échec à nos mouvements. On va prendre les fonctions qui marchent sur notre zippeur d'arbres binaires et les rendre monadiques. D'abord, occupons-nous des échecs possibles de goLeft et goRight. Jusqu'ici, l'échec de fonctions pouvant échouer était toujours reflété dans leur résultat, il en va de même ici. Voici goLeft et goRight pouvant échouer :
2.
3.
4.
5.
6.
7.
goLeft :: Zipper a -> Maybe (Zipper a)
goLeft (Node x l r, bs) = Just (l, LeftCrumb x r:bs)
goLeft (Empty, _) = Nothing
goRight :: Zipper a -> Maybe (Zipper a)
goRight (Node x l r, bs) = Just (r, RightCrumb x l:bs)
goRight (Empty, _) = Nothing
Cool, maintenant, si l'on essaie d'avancer vers la gauche d'un arbre vide, on obtient Nothing !
2.
3.
4.
ghci> goLeft (Empty, [])
Nothing
ghci> goLeft (Node 'A' Empty Empty, [])
Just (Empty,[LeftCrumb 'A' Empty])
Ça a l'air bon ! Et pour rebrousser chemin ? Le problème avait lieu lorsqu'on essayait de remonter alors qu'on n'avait plus de miettes, ce qui signifiait qu'on était déjà à la racine de notre arbre. Voici la fonction goUp qui lance une erreur si l'on ne reste pas dans les limites de notre arbre :
2.
3.
goUp :: Zipper a -> Zipper a
goUp (t, LeftCrumb x r:bs) = (Node x t r, bs)
goUp (t, RightCrumb x l:bs) = (Node x l t, bs)
Modifions-la pour échouer gracieusement :
2.
3.
4.
goUp :: Zipper a -> Maybe (Zipper a)
goUp (t, LeftCrumb x r:bs) = Just (Node x t r, bs)
goUp (t, RightCrumb x l:bs) = Just (Node x l t, bs)
goUp (_, []) = Nothing
Si l'on a des miettes, tout va bien et on retourne un nouveau point focal réussi, mais si ce n'est pas le cas, on retourne un échec.
Auparavant, ces fonctions prenaient des zippeurs et retournaient des zippeurs, ce qui signifiait qu'on pouvait les chaîner ainsi pour se balader :
gchi> let newFocus = (freeTree,[]) -: goLeft -: goRightMais à présent, au lieu de retourner un Zipper a, elles retournent un Maybe (Zipper a), et chaîner les fonctions ainsi ne fonctionnera plus. On avait eu un problème similaire quand on s'occupait de notre funambuleLe funambule dans le chapitre sur les monades. Lui aussi avançait un pas à la fois et chaque pas pouvait échouer parce qu'un tas d'oiseau pouvaient atterrir sur un côté de sa perche d'équilibre et le faire tomber.
Maintenant, nous sommes l'arroseur arrosé, parce que c'est nous qui essayons de nous déplacer, et on traverse le labyrinthe qu'on a nous-même créé. Heureusement, on peut apprendre de l'expérience du funambule et faire ce qu'il a fait, c'est-à-dire échanger l'application de fonctions normale contre >>=, qui prend une valeur dans un contexte (dans notre cas, un Maybe (Zipper a), qui a un contexte d'échec potentiel) et la donne à une fonction en s'assurant que le contexte est bien géré. Ainsi, tout comme avec notre funambule, on va échanger nos -: contre des >>=. Très bien, on peut à nouveau chaîner nos fonctions ! Observez :
2.
3.
4.
5.
6.
7.
ghci> let coolTree = Node 1 Empty (Node 3 Empty Empty)
ghci> return (coolTree,[]) >>= goRight
Just (Node 3 Empty Empty,[RightCrumb 1 Empty])
ghci> return (coolTree,[]) >>= goRight >>= goRight
Just (Empty,[RightCrumb 3 Empty,RightCrumb 1 Empty])
ghci> return (coolTree,[]) >>= goRight >>= goRight >>= goRight
Nothing
On a utilisé return pour placer un zippeur dans un Just, puis utilisé >>= pour donner cela à notre fonction goRight. D'abord, on crée un arbre qui a un sous-arbre gauche vide, et un sous-arbre droit avec deux sous-arbres. Quand on essaie d'aller à droite une fois, c'est un succès, parce que l'opération est logique. Aller deux fois à droite est aussi correct, on se retrouve avec un sous-arbre vide en point focal. Mais aller à droite trois fois n'a pas de sens, parce qu'on ne peut pas aller à droite dans un sous-arbre vide, c'est pourquoi le résultat est Nothing.
On a désormais muni nos arbres d'un filet de sécurité qui nous attraperait si l'on devait tomber. Ouah, cette métaphore était parfaite.
Notre système de fichiers a aussi beaucoup de cas pouvant échouer, comme lorsque l'on essaie de se focaliser sur un fichier inexistant. Comme exercice, vous pouvez munir notre système de fichiers de fonctions qui échouent gracieusement en utilisant la monade Maybe.
XV. Note de la rédaction de Developpez.com▲
Cet article est la traduction du livre Learn You a Haskell For Great Good!.
Nous tenons à remercier Valentin Robert pour la traduction, Winjerome pour la mise au gabarit et Claude Leloup pour la relecture orthographique.
